AI Segmentation & Sentiment Analysis
We noticed this through client interactions. Clients with hundreds of reviews lacked visibility into what customers were talking about. Difficult to think of corrective actions from reviews alone when all you have is a star rating.
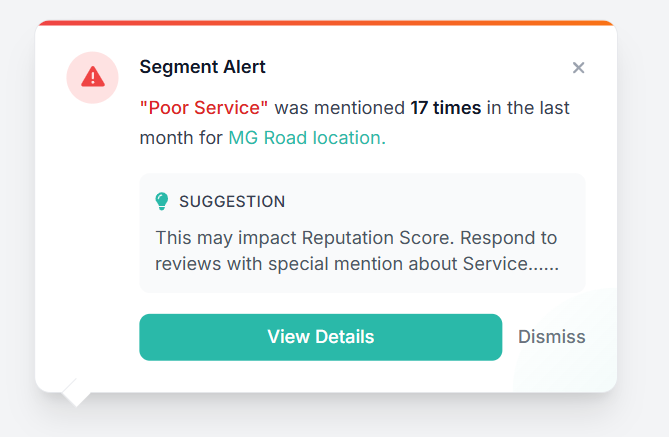
Segment alert in the product
Why we picked this up
From client interviews
This kept coming up. Across multiple client conversations, the same problem kept surfacing. That frequency made it hard to ignore.
Impact on their side
When clients cannot tell what is driving their ratings, they cannot act on it. The downstream effect on their operations was significant enough to prioritise.
Why AI and not something simpler
Every client had different segments, different terminology, different context. GenAI handles nuance and sarcasm well, and sentiment analysis is an established use case for it. That made the choice straightforward.
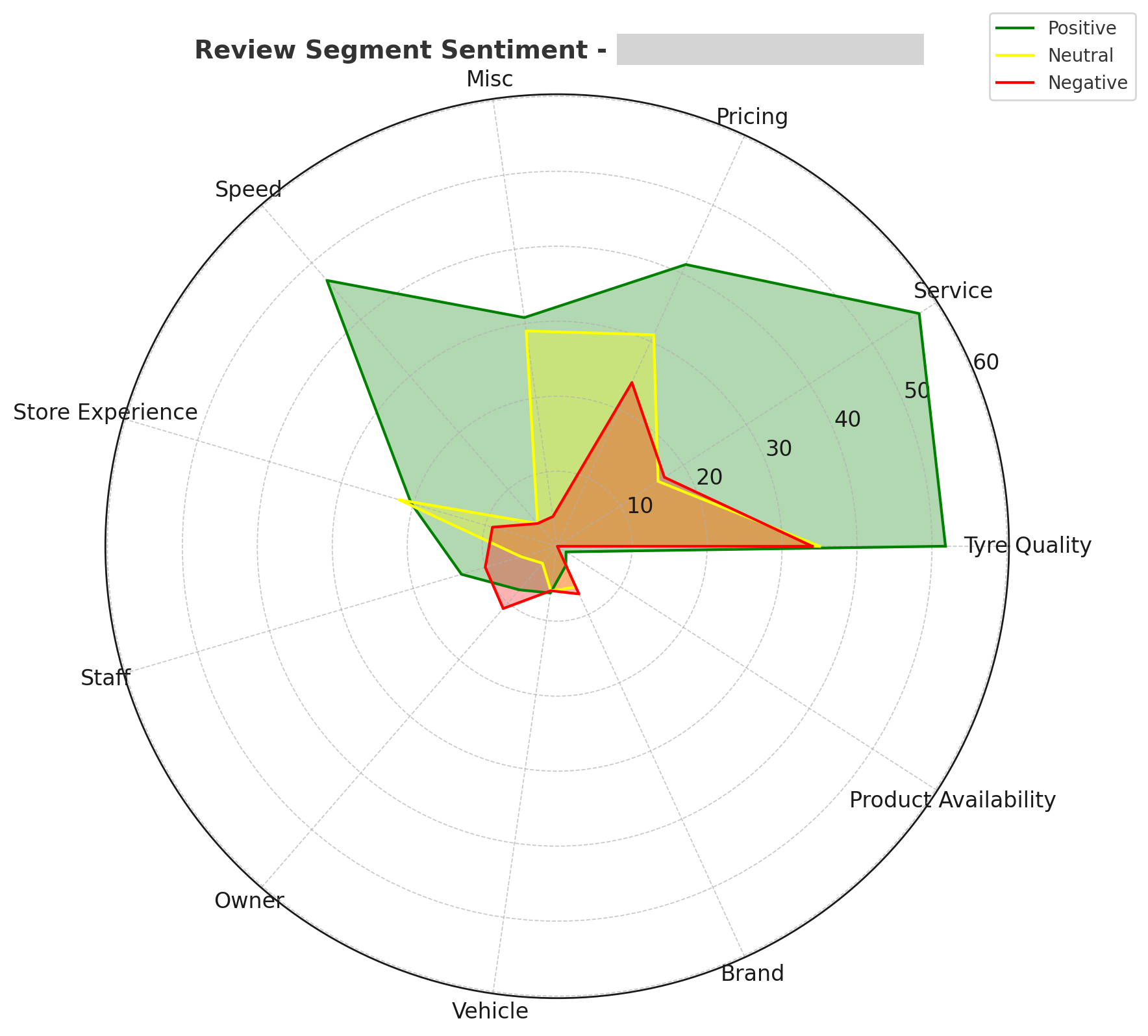
Segment sentiment across a pilot client location
What we built first
Piloted with 2 enterprise clients. The MVP extracted segments and sub-segments from reviews and assigned sentiment to each one: negative, neutral, or positive. This gave managers something they did not have before: a breakdown of what customers were actually talking about, by location.
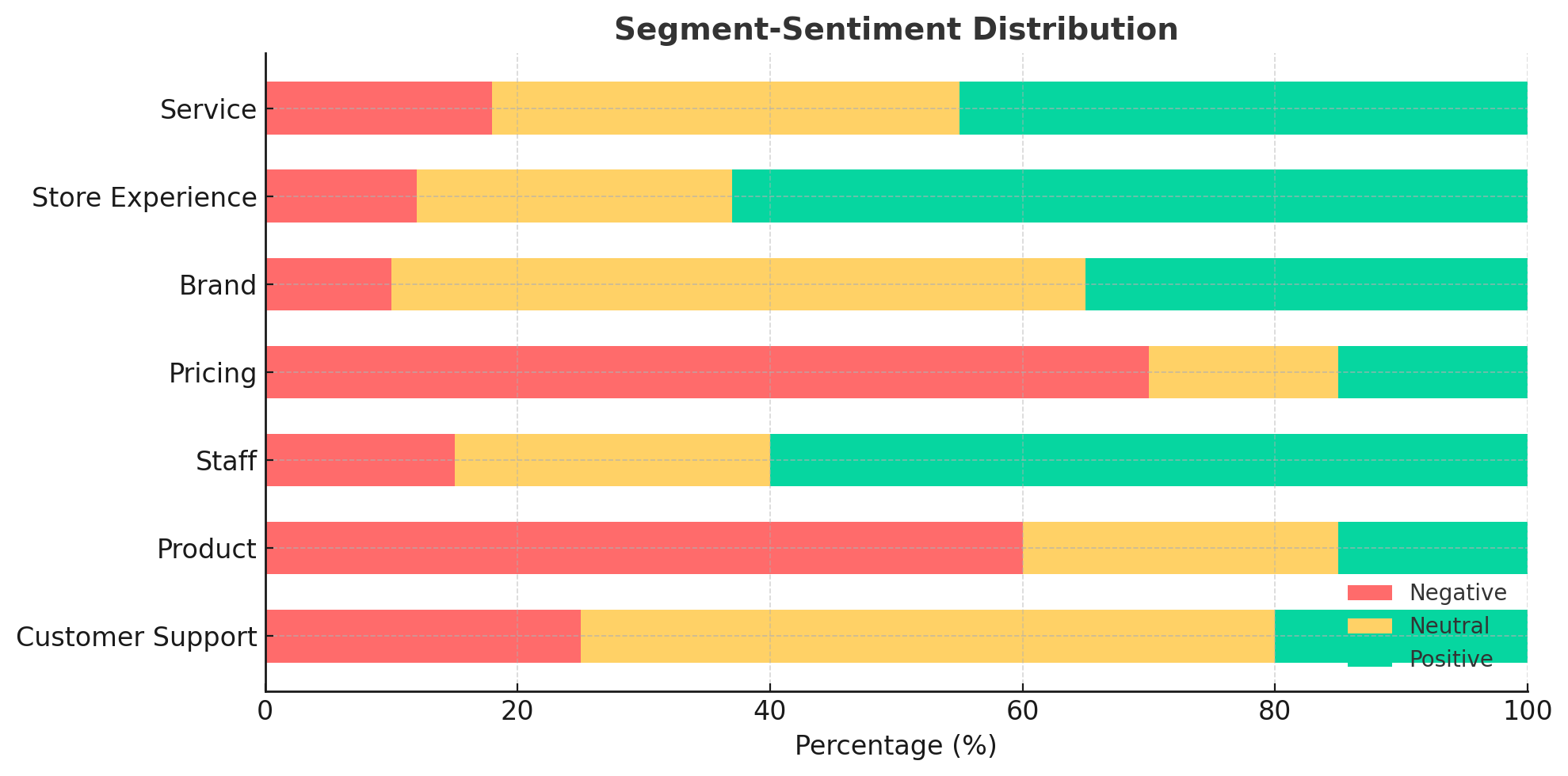
Segment-sentiment distribution across review data
Picking the right model
The MVP used OpenAI GPT-4o mini. Accuracy came out at 76.9%, which was on the lower side for a sentiment use case. We ran a comparison with open-source models to see if we could do better.
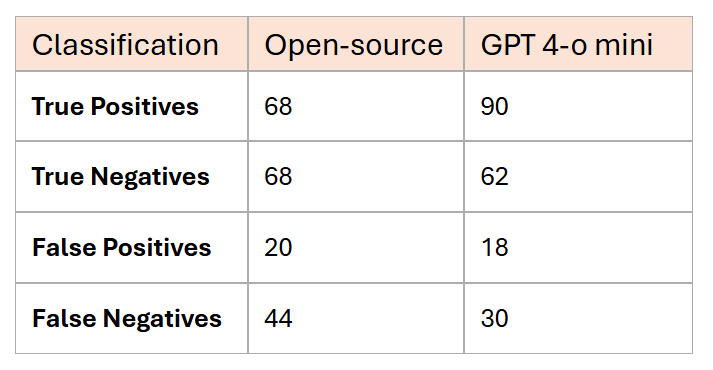
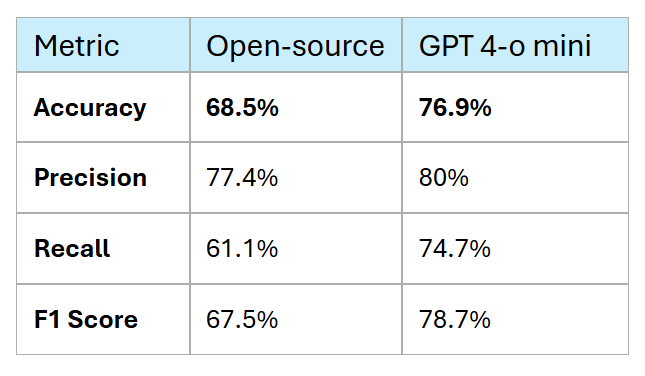
*Actual figures are masked to retain confidentiality
Training data: around 7000 total reviews, 200 samples, distributed across locations with a balanced sentiment mix.
What we did to improve accuracy
Threshold Tuning
Tuned sentiment classification thresholds (-0.2 / +0.2) to reduce misclassifications. This improved client trust in the output without retraining the model.
Prompt Improvement
Kept testing and iterating on our prompts. Small wording changes made a meaningful difference in how consistently the model classified edge cases.
Sensitive Review Handling
For industries like healthcare, some reviews needed extra care. If a review for a hospital mentioned a doctor by name and carried negative sentiment, we flagged it for a manual double check rather than auto-classifying it. Explainability mattered more than speed in those cases.
What changed after it went live
For clients
Location-level clarity
Clients could see exactly what to improve at each location, not just their overall rating.
Data over instinct
Instead of guessing what customers felt, they had actual segment-level data to act on.
For the product
Analytics adoption up
Specific analytics features saw increased adoption once segment visibility was available.
Fewer support queries
Clients were answering their own questions using the segment data.
What is still not perfect
Two areas where we are still relying on manual processes because automation is not reliable enough yet.
Industry-level segment accuracy
Segmentation accuracy varies by domain. A segment that works well for retail does not always translate cleanly to automotive or healthcare. We do manual sample monitoring to catch drift.
Explainability on sentiment
Especially in sensitive industries, automated classification is not enough. Manual sampling and evaluation is still part of the process.
More AI Product Work
Case Study
AI Review Responder
AI-generated responses for customer reviews. TAT reduced from days to hours, response rate lifted from 50% to 80%.
Read Case Study →Case Study
AI Content Studio
5-layer AI pipeline generating hyperlocalized social media creatives for automobile dealers.
Read Case Study →