AI Review Responder
Enterprises receive hundreds of reviews across their stores every month. Responding manually was slow and resulted in repetitive responses. Many reviews went unanswered. This was affecting Response Rate and TAT directly.
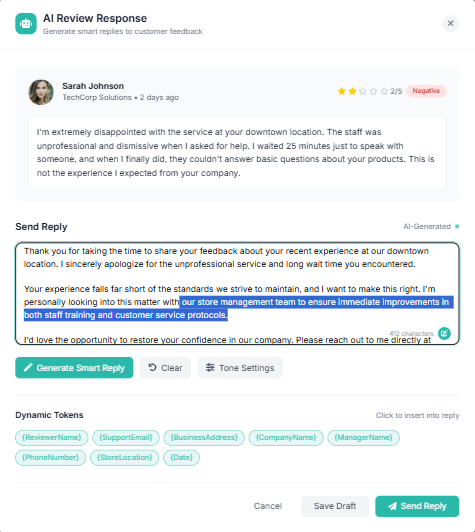
AI Review Responder in the product
Why we Prioritized it
Metrics that mattered
Response Rate and TAT carry high weightage in building Reputation Score. When these were slipping, it was hard to ignore.
Immediate pain for Account Managers
Responding to reviews manually was taking up a lot of their time. Repetitive work with no good solution in place.
Why AI and not templates
Templates get repetitive fast and they cannot adapt to the context of each review. A negative review about staff needs a different tone than one about wait times. AI enabled contextual, brand-toned and empathetic responses at scale. That is what templates and manual responses could not achieve.
What good output looks like
- Contextual to the specific review
- Brand-toned and empathetic
- Different enough across responses to not feel templated
What we built and how we tested it
Piloted with 2 enterprise clients. Iterated on prompts through the pilot. Human-in-the-loop was enabled so managers could edit before sending.
Output evaluation was based on
01
Output Quality
Tone and relevance to the specific review
02
Output Variety
Repetition check across generated responses
03
User Trust
Edit rate and qualitative feedback from managers
How we checked for repetition
One risk with AI-generated responses is that they start sounding the same. We ran a repetition evaluation on a sample of 50 responses to check how much variety the model was actually producing.
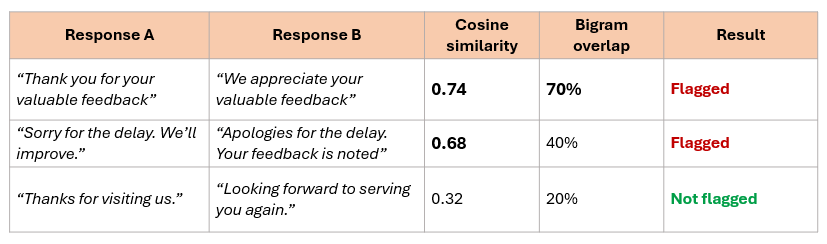
Cosine similarity and bigram overlap used together to catch both meaning and word-level repetition

24% flagged as repetitive
This was within an acceptable range. We got here after several rounds of prompt iteration. Actual figures are masked to retain confidentiality.
Cosine similarity threshold: 0.5 (meaning similarity). Bigram overlap threshold: 65% (word similarity).
What changed after it went live
For clients
50% to 80%
Average Response Rate improvement across clients
Days to hours
TAT reduction after AI responses were enabled
For the product
Analytics adoption up
Related Analytics features saw increased usage once Review Responder was live
AI differentiation
Strengthened the product's positioning as an AI-first reputation management tool
What we are still working on
Output Quality
Prompt iterations are ongoing. Each round improves tone consistency and relevance across different review types.
Vernacular Languages
Adding support for regional languages. A lot of reviews come in languages other than English and the response should match.
More AI Product Work